
Web scraping is one of my most common tasks and a bread-and-butter technique for anyone in the analytics world. It’s so common, I used it to help Julie while developing this blog.
At some point you’re going to need data. Not just data from a database or a csv file, but you’re going to need data you don’t already have. Real world messy data. With no SQL queries or simple APIs to save you, it’s time for web scraping.
While building out this blog, Julie wanted links to the articles she wrote on Data Shop Talk. After reviewing her author page on Data Shop Talk, I saw she had written well over 100 articles! Nice work, Julie! With that many posts, copy and paste won’t cut it (see what I did there…). However, with a little reconnaissance and few lines of Python, we can easily get those links.
Code requirements
For the coding, we’ll be using Python 3.7 and the following packages:
- Requests: gets the raw HTML of a page. Currently on version 2.
- Beautiful Soup: turns HTML content into an easy to use Python object. Currently version 4.
If you don’t have Python installed, follow these instructions.
If you’re new to working with packages, check out this post.
Setup
Both packages can be installed using pip. From the command line on OS X or Linux run:
pip3 install requests
pip3 install beautifulsoup4On Windows the packages can be installed by:
py -m pip install requests
py -m pip install beautifulsoup4Reconnaissance
It’s a good idea to spend time looking through the target page to gain an understanding of its structure. I went over to Julie’s author page on Data Shop Talk to see how the page was laid out. Each post shows up on the page inside a card like object with a title and meta data:
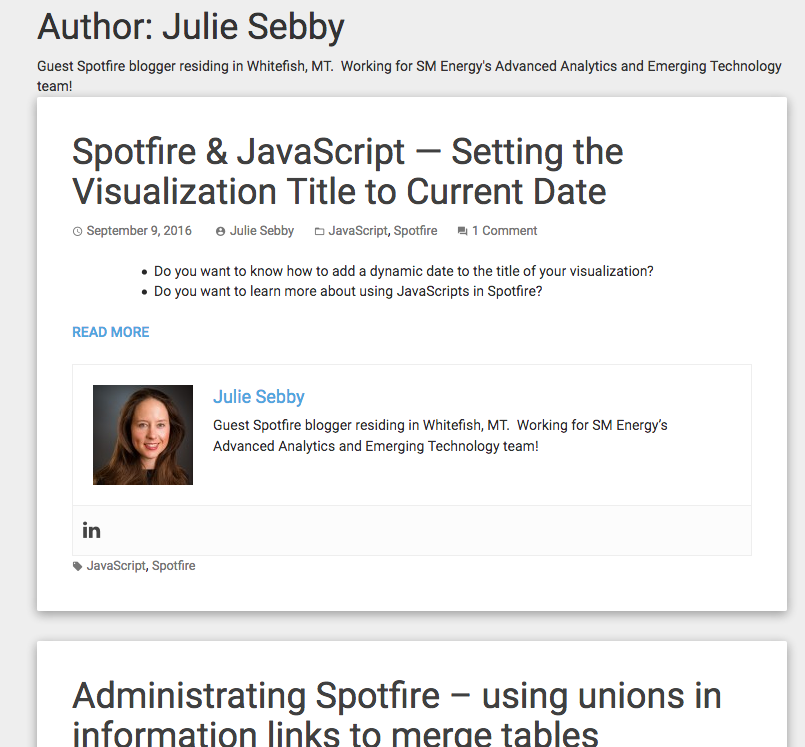
Clicking the title takes us to a new page with the entire contents of the post. The URL for this page is the data we want.
We’ll make use of some HTML knowledge moving forward. If you’re feeling a little rusty, Julie has a great series you can find here.
On the author page we can inspect the title and see what type of HTML element it is. Right click on the link and select ‘Inspect Element’:
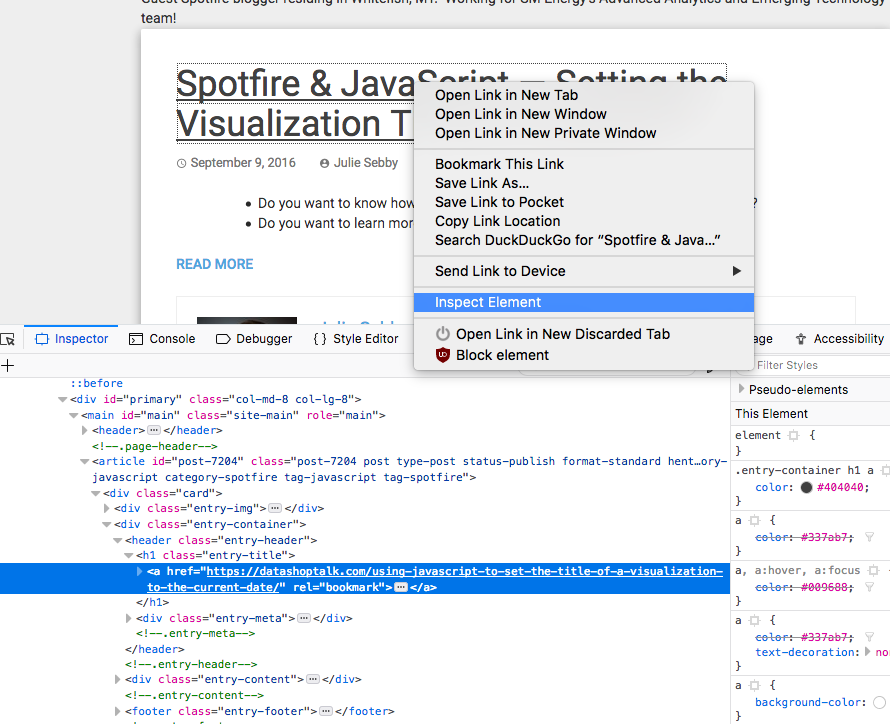
In the highlighted section we see an <a href> element (a link) contained inside an <h1> tag which makes that link a header. The header element has a unique class attribute that will distinguish it between other headers on the page. The nested structure of elements helps us find only the links that lead to an article.
We now have the following pieces of information:
- There are 15 pages of article previews with links we want. We’ll need to generate the URL and iterate over all 15 pages.
- The piece of data we want is the link within a header element with the unique class property ‘entry-title’.
While solving a technical problem, I always find it helpful to write the necessary steps out in plain English. This is commonly referred to as pseudo code. For the information we’ve uncovered, our steps look like this:
for each page:
find the link inside the headers with the class attribute: ‘entry-title’
print the URL of the linkYou’ll find writing code to be easier once you’ve worked out the pseudo code.
The Code
The python code follows the pseudo code pretty well.
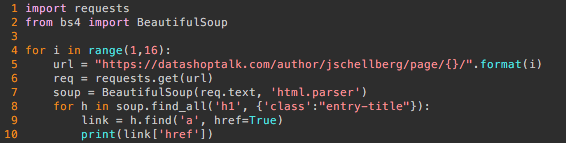
Here’s a quick break down of each line:
- 1-2: Import the requests package, and the BeautifulSoup function from bs4. More on modules and packages here.
- 4: Loop from i = 1 to i = 15 (total number of pages). More on loops here.
- 5: Create the URL for the author page.
- 6: Use the requests library to get the HTML content at that URL.
- 7: Use the BeautifulSoup function to create an easy to parse object from the HTML content. Since the input is HTML we specify that BeautifulSoup should use the ‘html.parser‘
- 8: For every header element with the class attribute ‘entry-title’ in that object:
- 9: Get the URL of the link inside the header (the string value of href=’URL’)
- 10: Print the URL to the output.
Final Thoughts
With a few lines of code we’ve collected the desired data and saved ourselves from the dreaded copy and paste hand:

Hopefully this real-world example has shown the usefulness of web scraping. More data is always better, and when you don’t have it, you’ll need to scrape for it.