Exporting to Excel is a very common task in Python, especially when developing. You might need to see an entire data set and be able to filter and sort on it, which is easier to do in Excel than with a print statement, or maybe you just need to send it to a customer for validation and testing.
This post will explain how to export to Excel using the pandas df.to_excel method and the pd.ExcelWriter class. pd.ExcelWriter and df.to_excel are closely related and often used together to write DataFrames to Excel. You can use df.to_excel by itself without pd.ExcelWriter. But, when you use pd.ExcelWriter, you will also use df.to_excel. Let’s get into the details.
df.to_excel
The df.to_excel method is used to write pandas DataFrames to an Excel file. With this method, you are allowed to….
- Specify the file path or an existing ExcelWriter object.
- Define the sheet name where the data frame will be written.
- Specify how missing data should be presented.
- Format floating point numbers.
- Control whether to write column headers and row names (or indexes).
- Specify the starting row and column.
- Choose the engine for writing to the data frame.
- Write MultiIndex and Hierarchical Rows as merged cells
- Freeze panes.
pd.ExcelWriter
pd.ExcelWriter is also part of the pandas library, but it’s a little different because it is a context manger. A context manager is a Python object that defines a runtime context for executing a block of code, typically used with the “with” statement. It ensures resources are properly managed, such as opening and closing files, acquiring and releasing locks, or setting up and tearing down connections.
With pd.ExcelWriter, you can write multiple data frames to different sheets, append existing files, apply custom formatting and control file locks, as previously described above.
- Writing data frames to multiple Excel sheets.
- Appending existing sheets.
- Control the behavior when writing to a sheet that already exists.
- Specify custom date and datetime formats.
- Filtering data.
- It supports different engines like xlswriter, openpyxl, and odswriter.
- Saving and closing the Excel file.
- Release file locks.
But as you’ll see in the code below, we use the functionality of df.to_excel when working with pd.ExcelWriter. And, many of the parameters that you need are still specified with df.to_excel. In other words, they work hand in hand. Let’s take a look at a few examples.
Setup
For my examples, I will read in a CSV file and then write it to Excel. You wouldn’t do this in real life, but I just need to get data into a pandas DataFrame.
- First, import the pandas library so we can use it.
- Second, store the file path of the CSV file in an object called well_list_file. If you are unfamiliar with the syntax used for the file path, check out this post.
- Third, put the well_list_file object into a pandas DataFrame called df_wells.

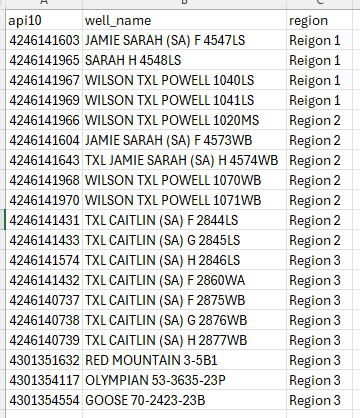
This is the data in the CSV file. Very simple.
Just Using df.to_excel
First, let’s look at the df.to_excel method. It is useful for simple (and single) exports to Excel. If you are developing and want to see results in Excel to check your work, this is a quick and dirty way to git ‘er done.
You can see all available parameters at this link. I’ve used a good number of them in my example, but the link will help you understand where there are defaults and which are optional.

Note that the column names are automatically included as headers in the Excel file without needing to specify the header argument. However, you can use the ‘header’ or ‘columns’ parameter to customize or change the headers. See the link above for more details.
Lastly, and very importantly, I have specified the file name ‘well_output.xlsx’, but where does this file get saved? By default, it will be saved to the current working directory. You can run this simple code to find out where your working directory is if you don’t know. You can also specify a full file path as I do in the next example.

Using pd.ExcelWriter with df.to_excel
As mentioned above, one of the advantages of pd.ExcelWriter is that it can write to multiple sheets, so let’s do that. I will filter my data by regions into 3 separate data frames and then write them to different worksheets.
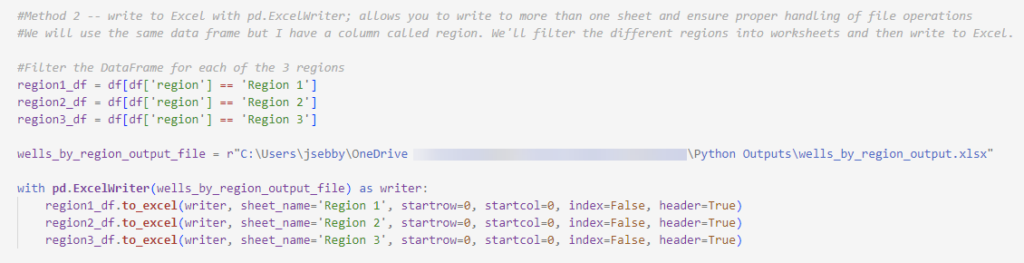
Notice that I created an object specifically to hold the full file path to tell Python where to put the output. If I had not done this, the output would have been written to my working directory.
Now, the code shown above is okay, but what if we had tons of regions or they changed. Instead of specifying them individually, we can use a for loop for more dynamic code. I use the .unique() function to create list of the unique regions. I put that into an object called “unique_regions”, and I reference it when using pd.ExcelWriter.

This will work much more dynamically than the code above.
Conclusion
In summary, you can use the pandas library to write DataFrames to Excel using either df.to_excel or pd.ExcelWriter. pd.ExcelWriter has more functionality, but when you use, it you also need to use df.to_excel.
Pingback: Understanding Your Working Directory When Working With Python – The Analytics Corner