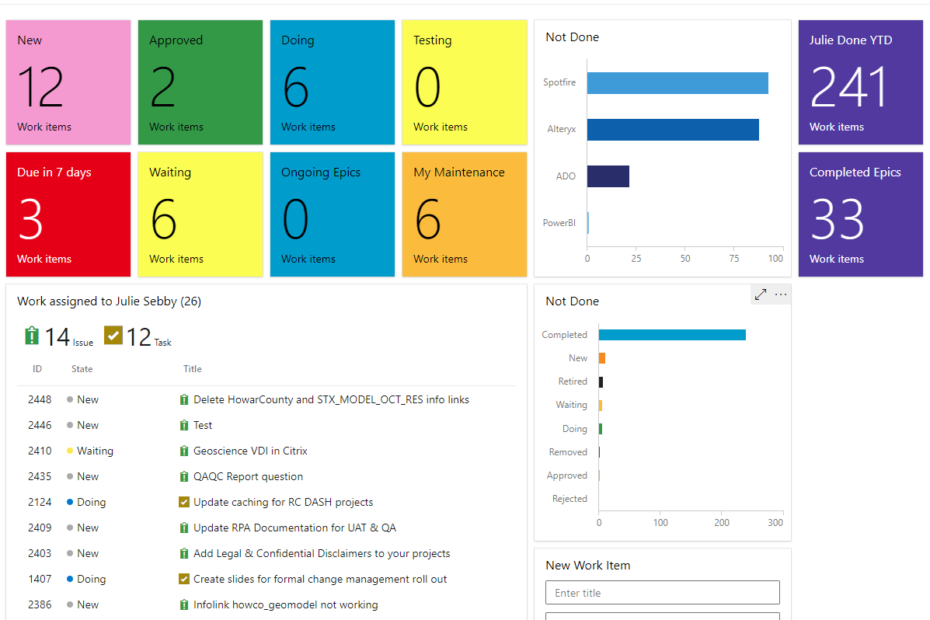
Last week, I kicked off a series that explains how we manage analytics assets with Microsoft Azure DevOps (ADO). I started by providing background information on our team structure, how we work, and the type of work we do. This week, I will explain ADO structure to provide context for how we use it, which will be the next post.
Azure DevOps Terminology & Structure
Now, I want to start with some basic ADO concepts so that my explanation of how we use ADO makes sense. And, it’s important to note that there is a lot of overlap in functionality in ADO. Microsoft did this intentionally so that you can fit the application to your own purpose.
The Big Stuff
- Organization
- First, organization is the highest level of hierarchy or organizational structure in ADO.
- You create one or more organizations in ADO.
- For reasons associated with cost, licensing, streamlining, etc, we have a single organization.

- Project
- Next, project is the second level of hierarchy or organization in ADO.
- It’s up to you to determine what constitutes a project. But, know that processes are set for each project (see Process).
We have a LOT of projects under our single organization. For example, the BI team has one project for support, maintenance, and ad hoc work called AAET_BI_Work. But, we also create a project for each sprint, which may generate one or more analytics assets. The other AAET teams — RPA (Robotic Process Automation) and AI/ML (Artificial Intelligence/Machine Learning) — create a project for each analytics asset they build because they are larger and more complex solutions.
- Process
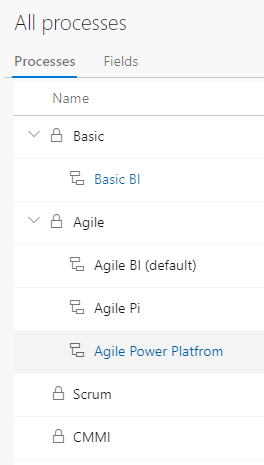
- The process dictates the work items available for use in a project.
- A project uses one and only one process.
- Different projects can use different processes.
- The available processes are Basic, Agile, Scrum and CMMI.
- To customize a process, you must clone it (copy it) or else you will impact every project using that process. Thus, you can only customize cloned processes.
The Details
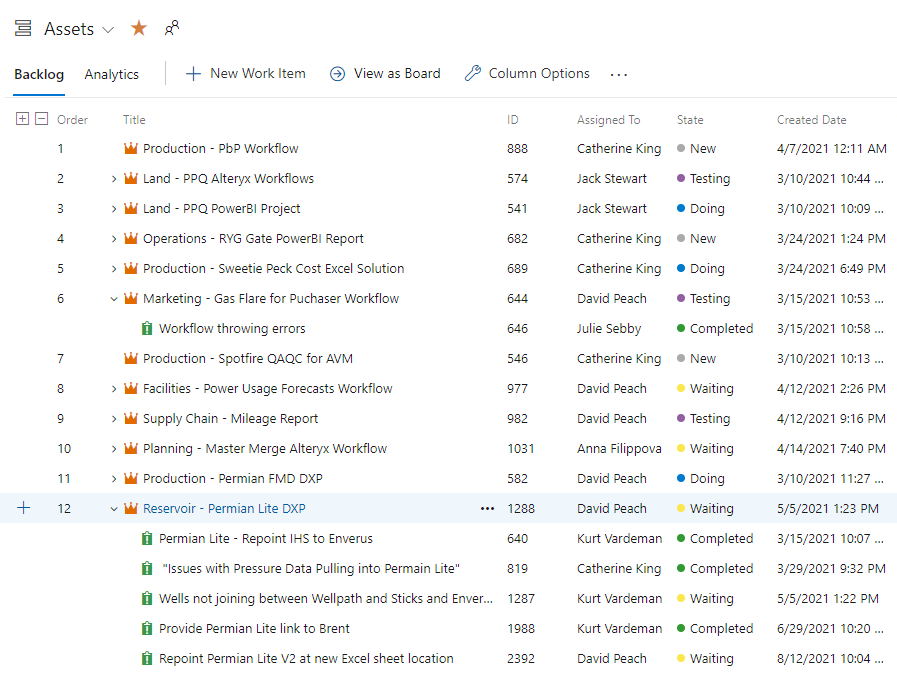
- Work Items
- ADO uses work items to organize work.
- Work items are hierarchical.
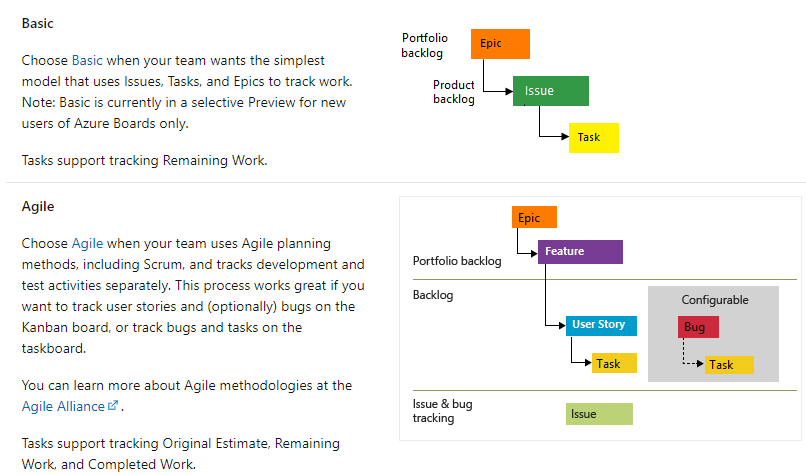
- The process selected determined the work items available.
- Examples of work items include Epic, Issue, Task, Feature, Bug, User Story.
The screenshot below gives you an idea of the hierarchy and various work items associated with each process.
- Teams
- Next, teams are created from within each project.
- A project can have one or more teams.
- Teams have their own backlog.
- A team represents whatever you want it to represent.
- An administrator assigns individual members to teams. Members can only see work items they when they are part of a team.
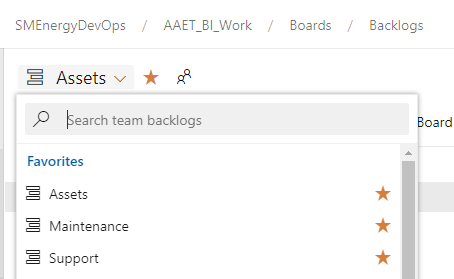
- Backlogs
- Finally, each team has its own backlog.
- Backlogs are a way to organize work that needs to be done.
Tying Everything Together
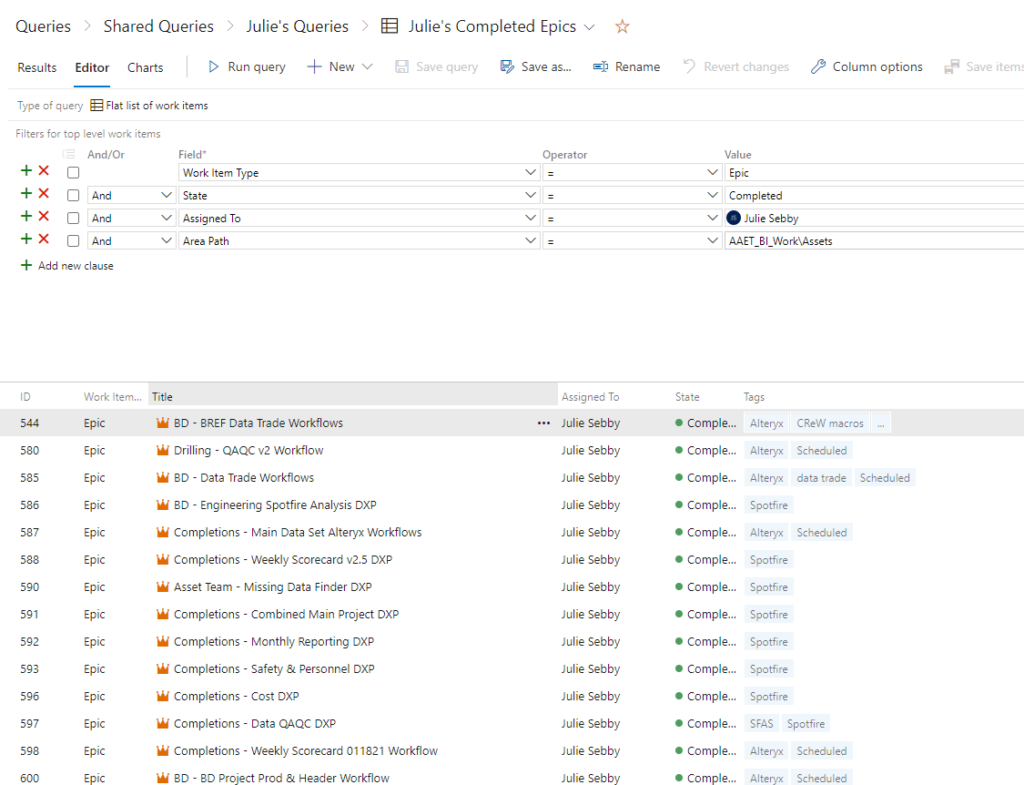
- Queries
- Queries drive Dashboards (see below). You cannot create a Dashboard without a query.
- Everything in ADO is queryable.
- Queries must be shared to be use in Dashboards.
- Dashboards
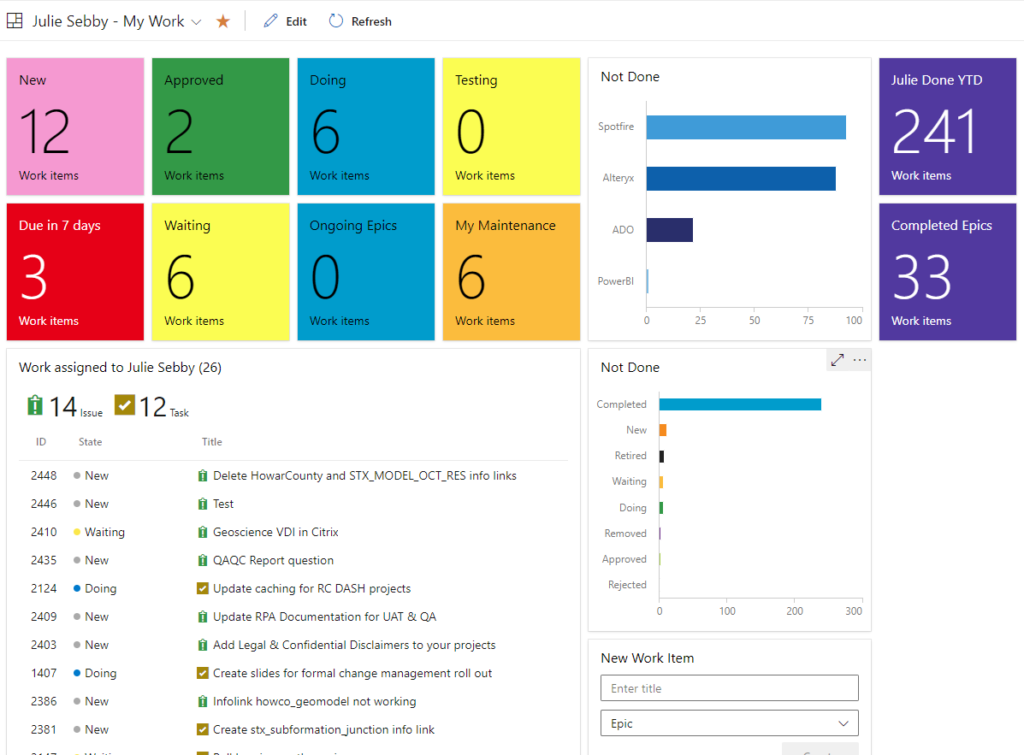
- Dashboards summarize data and help you navigate ADO.
- Build dashboards with different types of widgets. I like summary tiles.
- Clicking on a widget will take you to a list of work items or a specific items so that you can get more details.
Wrap Up
Eventually, there will be more structure and terms to understand like Area Path and Iteration. For now, this is a good start to understanding Azure DevOps. Next week, I’ll get into how we use ADO structure to manage analytics assets.