This is my second post discussing a large PDF processing automation project. In the first post, I focused on how to bring data into PAD from Excel, transform that data from a table to a list, and remove nulls from the list. Now, I want to talk about how I use OCR in Power Automate Desktop to translate PDFs to text and look for specific keywords. Check out this post for the details.
Use Case for Searching PDFs
To begin, let me explain my project. I’m working with our Tax & Accounting group to make sure we properly classify costs. We have a transactional finance system and processing on every line item detail in every invoice. But, if vendors don’t put detail in the right place on an invoice, it can be difficult.
Without automation, analysts have to open hundreds of invoices and manually look for keywords. Clearly, that’s terrible, and the goal is to automate that part of the process.
Now, this is a work in progress. So, there might be additional automation steps to download PDFs. But for now, the files have been downloaded for me. I begin with a folder of PDFs.
Power Automate Desktop will perform the following tasks.
- Pull in a list of keywords from Excel (last week’s post)
- Open PDFs one at a time
- Use OCR to convert each page to an image and search the image for text
- Loop thru the text from each image to identify keywords
- Write the results of the search in Excel
This blog post will focus on the OCR.
What is OCR?
OCR stands for optical character recognition. OCR is the process that converts an image of text into a machine-readable text format. PAD has 2 OCR engines – Windows and Tesseract. The primary difference between them is the language being extracted and whether or not additional language pack installation is required. You can also use Tesseract to extract from multilingual documents.
For any OCR project, I always test both engines to see which works better. They don’t always perform the same.
OCR in Power Automate Desktop
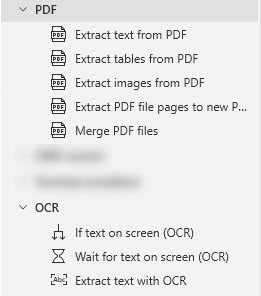
The options you’ll need to work with OCR are in the PDF and OCR submenus of the Actions menu. When working with PDFs specifically, I stick with the actions under the PDF menu.
Now, with this particular project, my PDFs are scanned paper copies. A vendor actually prints out pieces of paper. Some of the content is filled out by hand (paper form). Next, it is physically handed over and hand stamped. Then, it’s scanned in as a PDF document for lucky me to work with. This is important because this type of PDF is different from a Word document that you save as PDF (without any handwriting). Fortunately, I don’t need to search the handwriting. But, it does mean that some actions in PAD don’t work.
In the screenshot below, I’ve added all three of the available actions to extract data from a PDF — table, text, and images.

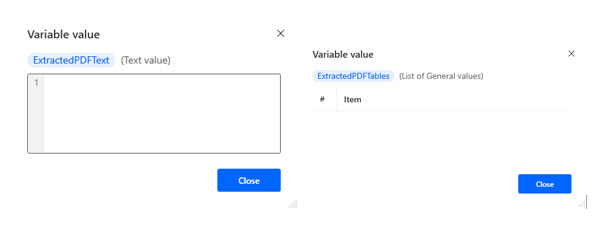
If I run PAD, this is what comes back from ExtractedPDFText and ExtractedPDFTables. Nothing. I get nothing. It doesn’t read text or tables from the PDF because it is a scanned paper document, which is essentially an image.
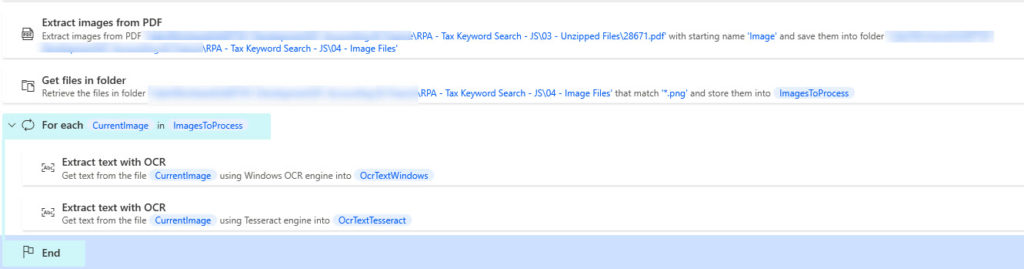
So instead, to make this work, I ask it to extract the image first and then extract text with OCR from that image. My first step is to extract the image from the PDF. This action will produce one .png image per PDF page. Then, I use Get files in folder to bring in all the images. Next, I loop over each one of them. Now, for simplicity, I only put the Extract text with OCR actions within the loop, which will overwrite the content of OcrTextWindows and OcrTextTesseract for each image processed. That’s not ideal in the real world, but right now we’re just talking about the OCR basics. My next post will show more of my real-world solution.
The OCR Engines
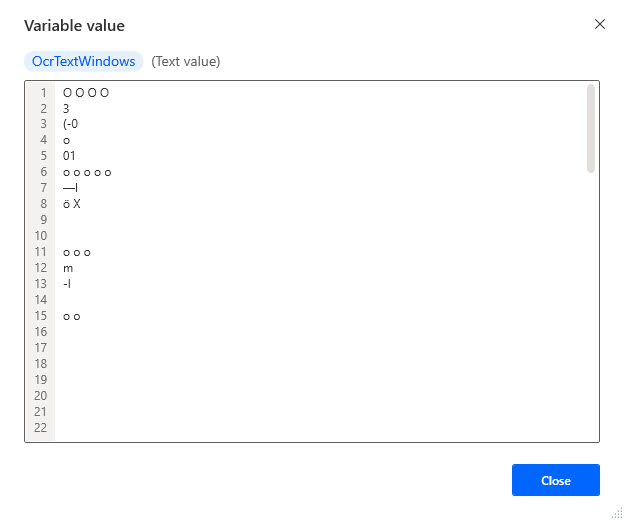
Below, you can see the result from the Tesseract engine. It is usable content from my invoice.
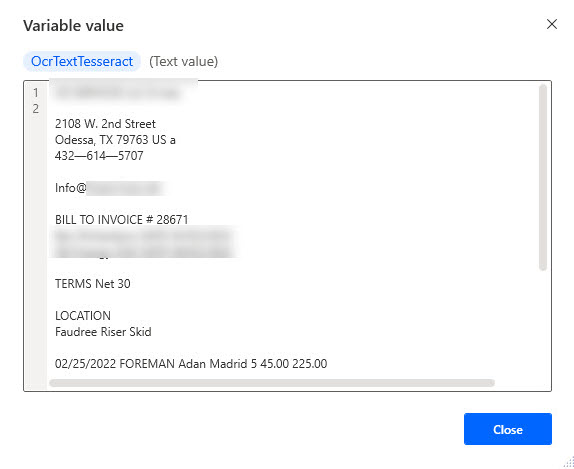
The result from the Windows engine is jibberish and not usable. Therefore, this project will use the Tesseract engine. For the record, I’ve had it go the opposite way where the Windows engine produced the better result, which is why I test every time.
What Did We Learn
So, what did we learn?
- There are 2 OCR engines in PAD.
- They don’t always produce the same output.
- The OCR actions in PAD live in the PDF and OCR submenus.
- Sometimes PDF content must be converted to an image and then read with OCR to get a good result.
The next post will focus on how I use loops to make this work with multiple PDFs and multiple images.
Pingback: 4 Things I Misunderstood About Power Automate » The Analytics Corner
Pingback: How to Fix Data Gateway Error in Power Automate » The Analytics Corner