- Have you noticed key columns for linked data in Data Table Properties and just want to know more?
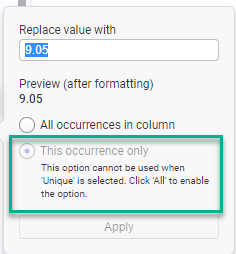
- Have you tried to use replace value transformations but found options grayed out (screenshot above)?
- Have you ever lost the marked data behind tags when opening or closing a file?
- Would you like to be able to edit values in a data table?
If any of these apply, read on to find how what key columns are and how to use them.
Key Columns
Key columns define the granularity of a record. They tell Spotfire which columns make a record unique so it can find the record again. This is useful when you need to recall marked data with tags or replace values in a data table. We’ll look at each of these use cases individually. First, let’s talk about how to set up key columns.
Key Column Setup
Key columns for linked data are setup in Data Table Properties.
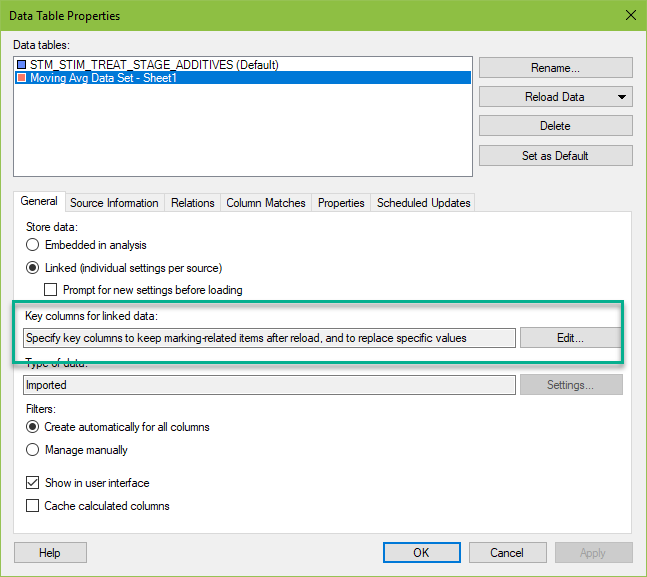
If you click on the Edit button, it will bring up this dialog.
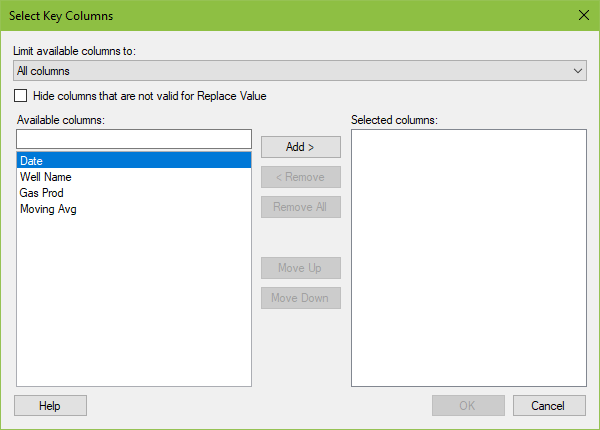
The dropdown will default to “Columns of appropriate data types”. I’m not certain how Spotfire defines appropriate. In any event, I just change the dropdown to “All columns” because I know how to define the granularity of my data. The limiting is merely an attempt to help filter down columns for the user.

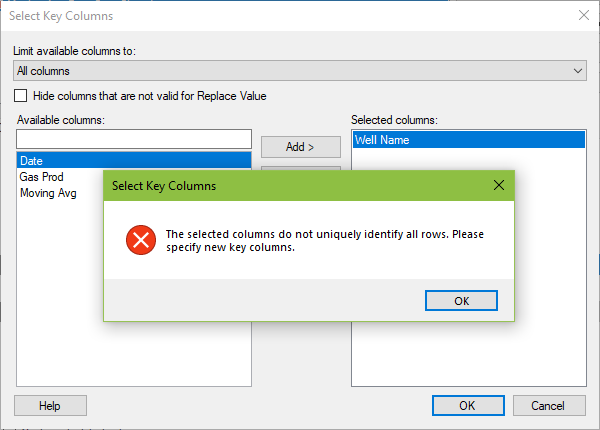
In this dialog, move columns from left to right to define the granularity of the record. For example, if you are working with a well header table or a customer table, where you have one record per well or one record per customer, the table will contain a well or customer identifier, such as API number or customer ID. The keyword here is unique. If the data set contains more than one record with the same API or customer ID, Spotfire will give the error message below. In this case, you’ll need to add another column to define uniqueness.
Let’s use a production data set as another example. In a production data set, you have one record per well per day. In this case, you would need to use the well identifier column, like API, and the production date column. The combination of these columns uniquely identifies the record.
Pro Tip!
You can also use this Spotfire function to identify the uniqueness of a record if you aren’t familiar with the data set. Take your best guess at which columns make a record unique. Spotfire will tell you if this is correct.
Now, that you know how key columns are set up, let’s talk about what you can do with them. I’m going to cover two use cases — tags and transformations. First, let’s look at how this applies to replace value transformations.
Replace Value Transformations
In one of the last updates, Spotfire added transformations that allow users to replace a specific value or replace a value in a data table. This function is visible in three locations. First, you can see it in the Transform data dialog from the Data menu.
Second, it’s also an option if you double click on a cell in a data table or in the Details on Demand panel.
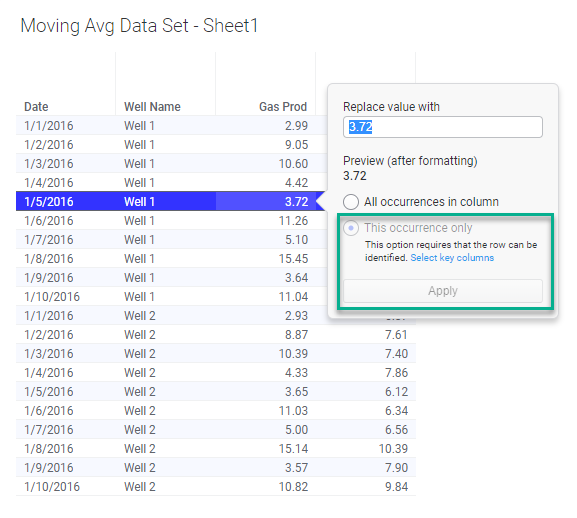
Third, you’ll also see it as an option in the Data panel.
Now, what you might notice about the screenshots above is that some of the options are grayed out. This is because key columns are not setup. In the screenshot above, Spotfire will allow the user to replace all occurrences in a column (replace a value). However, it has grayed out the option to replace a single occurrence. That’s because it doesn’t know how to identify the row. This is what key columns are for.
Here is a bigger copy of the screenshot so you can see the grayed out portion. Once key columns are set, this feature is enabled. Now, you can replace a single value within a data table.
Now, let’s talk about the other use case — recalling marked data with tags.
Key Columns for Tags
If you aren’t familiar with Spotfire’s tags feature, check out the post I wrote on How to Use Tags or the Differences Between Bookmarks, Tags, and Lists.
To briefly summarize, tags are used to recall marked data. They have their own panel, which can be turned on from the View menu. Users create a tag collection, create individual tags, and then assign marked data to each tag.
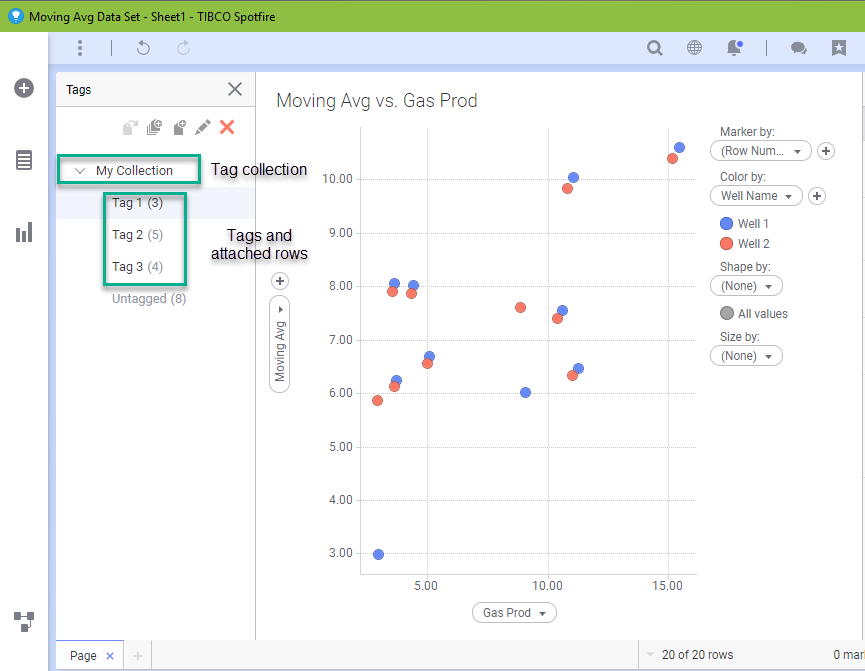
Now, this is all fine and good until you close the DXP. If you close the DXP without assigning key columns, the marked data attached to tags will be lost. If you haven’t experienced this, you would reopen the file and instead of seeing numbers next to each tag, there would be zeros. Losing the marked data defeats the purpose of creating them in the first place. But, if you set up key columns, Spotfire will remember the marked rows.
Conclusion
To summarize, key columns for linked data help Spotfire identify individual records. They are useful for retaining marked data with tags and enabling the replace unique values transformation.
Spotfire Version
Content created with Spotfire 10.2.
If You Enjoyed This…
Check out some of my other posts on transformations like How to Transform Multiple Column Names at Once.